




🌟 Welcome to Apache Kafka Intro Blog! 🚀
Ready to master messaging with Apache Kafka? Whether you're new to batch processing or a seasoned pro, join us as we explore Apache Kafka from start to finish.
In this series, we'll cover everything you need to know to streamline your data processing workflows. Get ready for practical examples, best practices, and insights to elevate your message processing skills.
Let's dive in and unleash the power of Apache Kafka together! 🌐💼💡 Stay tuned for our first installment. Happy messaging! 🎉👨💻
Introduction
Apache Kafka in open source distributed streaming process software, that is used to handle real-time data. It is a publish-subscribe messaging system, that lets us exchange the messages between the applications.
Before we deep dive into Kafka, lets learn about the messaging system.
What is Messaging System??
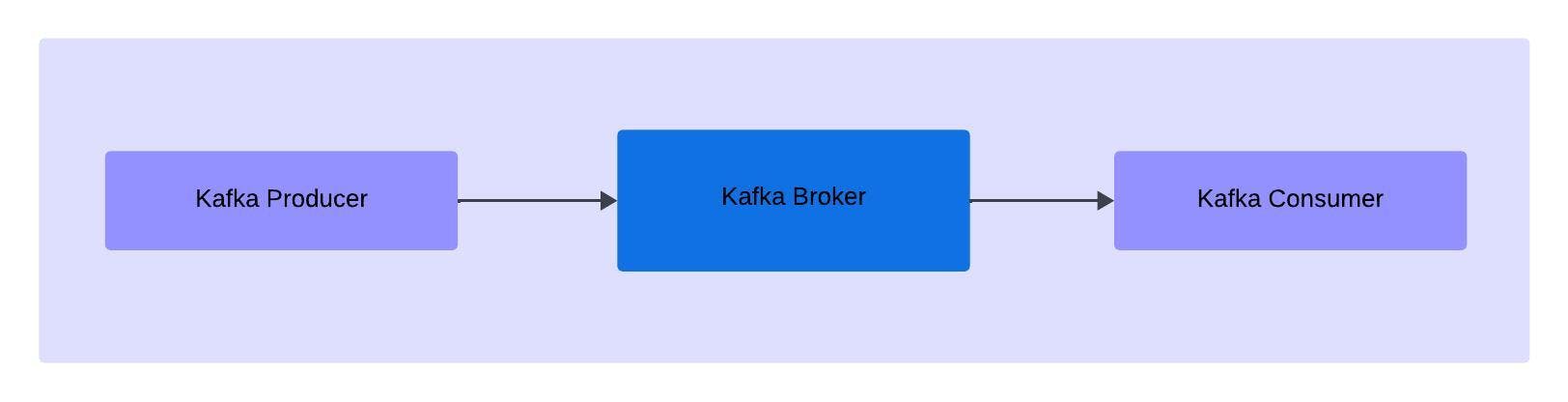
The messaging system is a simple exchange of messages between the persons, servers or applications. A publisher - subscribe system allows to exchange the message between the sender and receiver. In Apache Kafka, we call the sender as the Kafka Producer that sends the messages to the broker (Apache Server), from which the receiver, Apache Consumer reads the messages.
Let's see some of the core concepts of the Kafka!
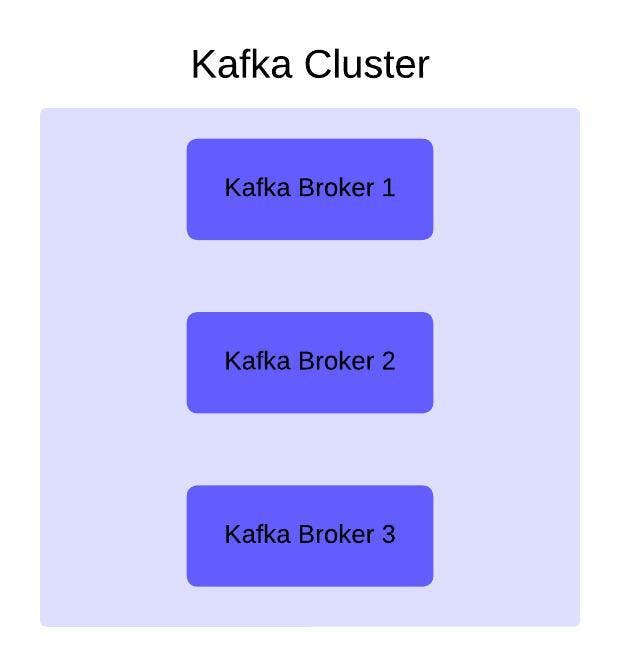
Kafka Cluster
In Apache Kafka, clusters are groups of brokers (or servers), since kafka is distributed messaging platform, a cluster must have a minimum of 3 Kafka Broker (or Kafka Server).
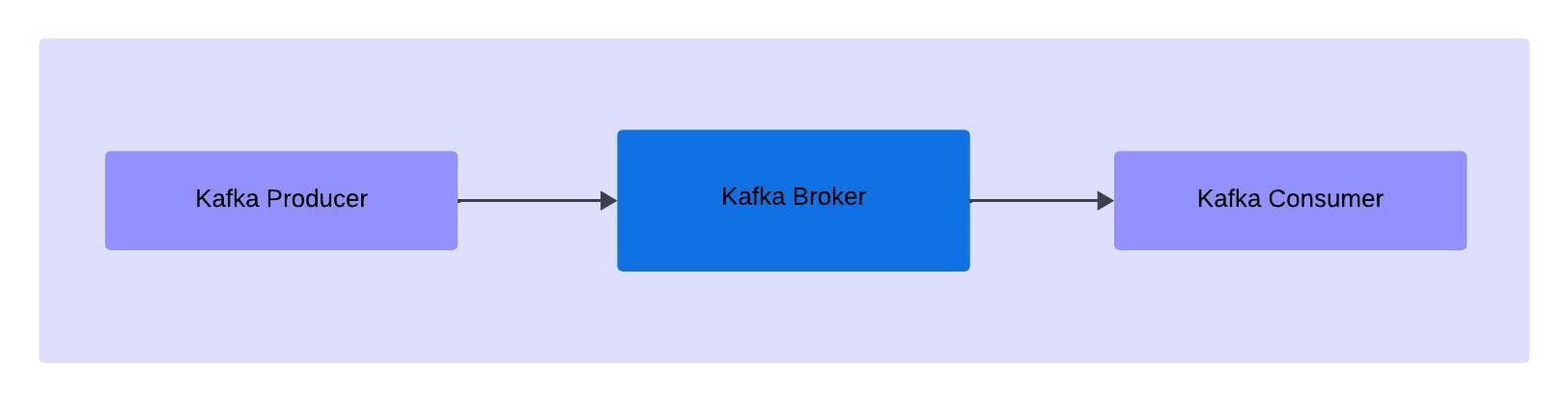
Kafka Broker (Kafka Server)
Kafka Broker (Kafka server), as the name suggests, it acts as moderator between the producer and consumer.
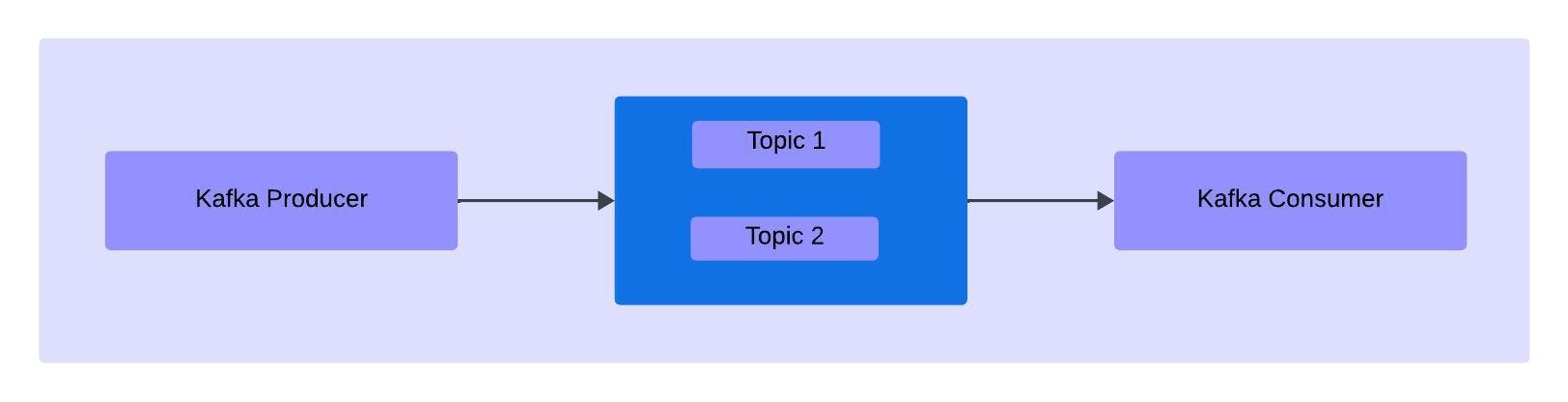
Kafka Topic
Kafka topics are like the tables in the database, which we would be using to store the similar stream of data. Topics are used by the producer to store the data, and by the consumer, to read the data.
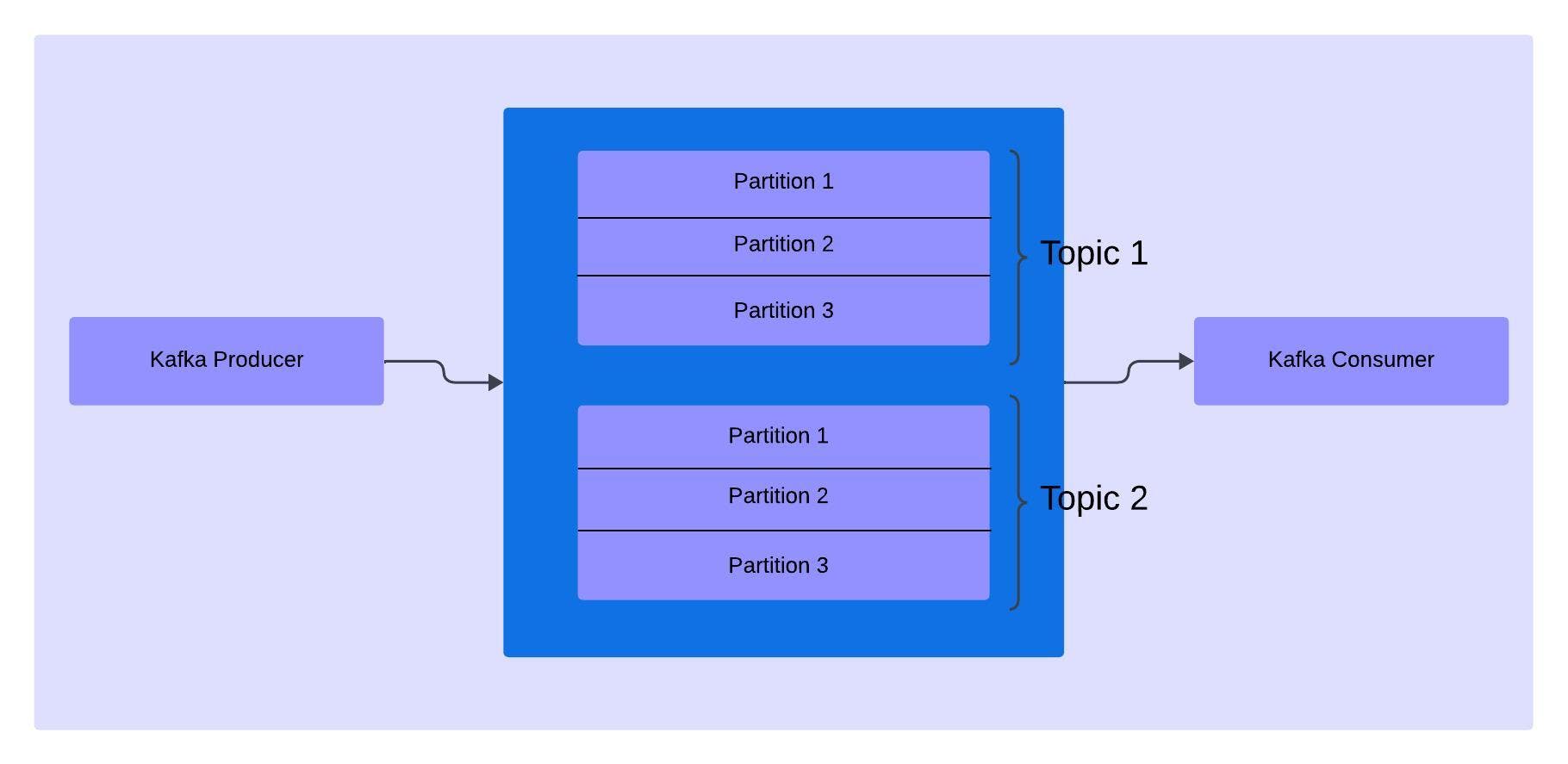
Kafka Partitions
Kafka Topics are split into number of topics, the messages sent by the producer are stored in these partitions. Due to there is need to mention the number of partitions required while creating the topic.
Kafka Producer
In Apache Kafka, the Kafka Producer sends the messages to the Kafka Broker (or Kafka Server), since it's a pub/sub model the Kafka broker acts as a moderator. Kafka Producer doesn't directly send the messages to the Consumer.
Kafka Consumer
Kafka Consumer reads the messages from the Kafka Broker, whenever the messages are available to it. Any consumer who wants to read the messages can subscribe to the topic in order to read the data.
Installation: Apache Kafka on Windows
Visit the official Apache Kafka Downloads page and download the zip file (download the binary files).
Once downloaded, a
kafka_2.13-3.7.0.tgzwould be downloaded, then open the directory in the command prompt.To extract the file, enter the below command:
tar -xzf kafka_2.13-3.7.0.tgz
Setup: Apache Kafka
Navigate to the extracted folder.
Now, we need the configure the zookeeper directory, navigate to the
config/zookeeper.propertiesfolder.In
zookeeper.propertiesfile, change the value atdataDir=to<parent_directory_of_kafka>/zookeeper-data.Now, navigate to the
config/server.propertiesfile, change the value for thelog.dirs=to<parent_directory_of_kafka>/kafka-logs.
Starting Up: Apache Kafka (with zookeeper)
Navigate to the Kafka directory.
Initially we need to start the zookeeper server, by the following command.
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesNow, start the kafka server, by the following command.
.\bin\windows\kafka-server-start.bat .\config\server.properties
Starting Up: Apache Kafka (with kraft)
Navigate to Kafka directory.
Here, we will create a
clusterId, which we will then use to create a topic where all the metadata is stored..\bin\windows\kafka-storage.bat random-uuidNow, will use this random UUID as
CLUSTER-ID, to format the log directory that stores metadata..\bin\kafka-storage.sh format -t <CLUSTER-ID> -c config\kraft\server.propertiesThen we will simply start the Kafka Server
.\bin\kafka-server-start.sh config\kraft\server.properties
There is no need to format the log directory every time you run the kafka server, simply execute the command to start the kafka server.
Conclusion
Thanks for reading our latest article on Apache Kafka: CLI Tutorial with practical usage.
Happy messaging!!!!😊